This is an old revision of the document!
Table of Contents
Project Name:
- Proposed name for the project:
Data Plane Acceleration - Proposed name for the repository:
dpacc - Project Categories:
Requirements
Project description:
As a result of traffic convergence feature and the pervasive real-time high performance requirement for traditional data plane devices, combined with the inability to carry out computational-intensive tasks cost-efficiently by general CPU, various hardware acceleration solutions optimized for specific tasks are widely applied in traditional data plane devices, and is expected to continue to be a common practice in virtualized data plane devices (i.e. as VNFs).
- Usecase1: Packet processing
- Usecase2: Encryption
- Usecase3: Transcoding
The goal of this project is to specify a general framework for VNF data plane accelertion (or DPA for short), including a common suite of abstract APIs at various OPNFV interfaces, to enable VNF portability and resource managment across various underlying hardware accelerators or platforms.
By utilizing such cross-usecase, cross-platform and cross-accelerator general framework, it is expected that data plane VNFs can be easily migrated across available platforms and/or hardware accelerators per ISP’s demand, while the ISPs could also change the platform or apply new hardware/software accelerators with minimal impact to the VNFs.
As shown in the following figure, there are basically two alternatives for realizing the data plane APIs for a VNF. The functional abstraction layer framework and architecture should support both, and provide a unified interface to the upper VNF. It will be the person configuring the VNF, hypervisor/host OS and hardware (policies) that decides which mode to use.
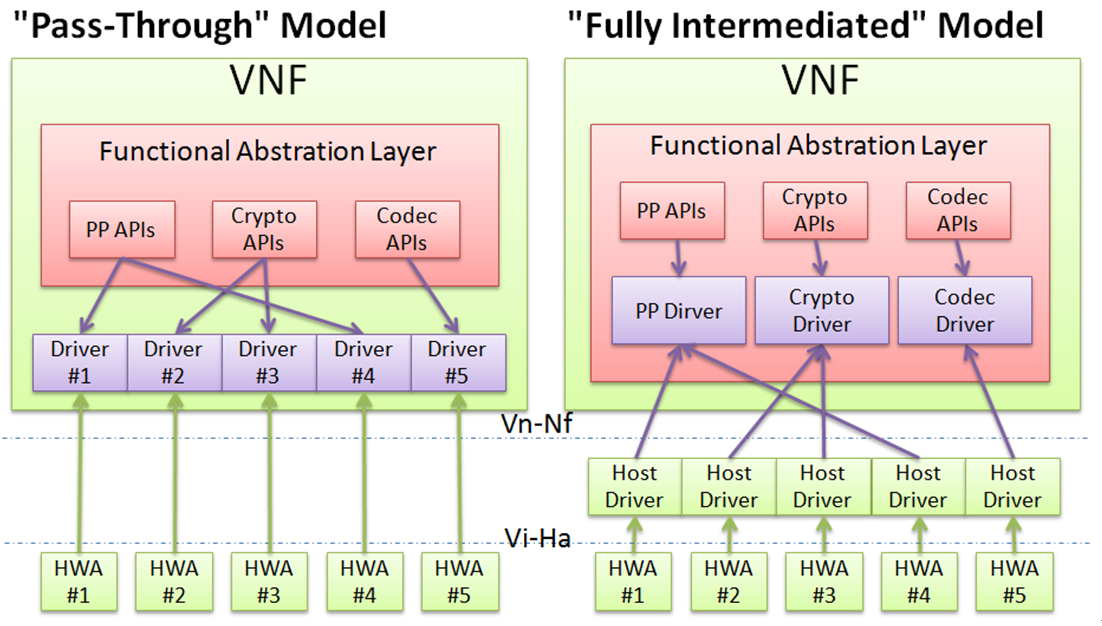
Note: for simplicity, the figures are drawn for hardware offloading accelerators (or HWAs) on the local hardware platform, but the scope of this project is by no means limited to local hardware acceleration.
The “pass-through” model where the VNF is making use of a common suite of acceleration APIs in discovering the hardware accelerators available and using the correct and specific “direct drivers” to directly access the allocated hardware resources. The features of this model include:
- It enables the most efficient use of hardware resources by bypassing the hypervisor/host OS, yielding higher performance than the other model.
- It cannot provide “absolute transparency” to the VNFs using hardware accelerators, as they have to upgrade to make changes to their VM image each time they are making use to a new type of hardware accelerator, to load the specific driver and make it known to the application.
The “fully intermediated” model where the VNF talks to a group of abstracted functional “synthetic drivers”. These “synthetic drivers” relays the call to a backend driver in the hypervisor that actually interacts with specific HWA driver. The features of this model include:
- Through this intermediate layer in the hypervisor, a registration mechanism is possible for a new HWA to make them mapped to the backend driver and then be used automatically without any change to its upper VNFs.
- Access control and/or resource scheduling mechanisms for HWA allocation to different VNFs can also be included in the hypervisor to enable flexible policies for operation considerations.
Scope:
- Problem Statement
As stated earlier, despite of the fact that hardware assisted data plane acceleration is expected to be a common practice in production data plane VNFs, currently there is no common interfaces existing for VNFs to use for accessing these specialized hardware accelerators.
As a result, the VNF developers have to rewrite their code to do hardware migration, which leaves them reluctant to support new acceleration technologies available, while ISPs have to suffer from the undesirable binding between VNF software with the underlying platform and/or hardware accelerator in use.
By specifying a common suite of hardware-independent interfaces for data plane VNFs, at least the upper service handling layer implementation can be fully decoupled from the HW architecture, fulfilling the OPNFV’s vision towards an open layered architecture.
To this end, the proposed project is intended to
Phase 1: (by 2015Q2)
- document typical VNF use-cases and high-level requirements for the generic functional abstraction for hardware acceleration;
- identify the potential extensions across various NFV interfaces and evaluate current state-of-art solutions from open-source upstream projects according to identified requirements and targeted framework
Phase 2: (by 2015Q4)
- specify detailed framework/API design/choice and document test cases for selected use-cases;
- provide open source implementation for both the framework and test tools; and
- coordinate integrated testing and release testing results.
- Interface specification
Using the small cell GW VNF as an example, where the VNF is composed of a signaling GW (SmGW) VM and a security GW (SeGW) VM. In this example, SmGW VM is using hardware acceleration technology for high performance packet forwarding, while SeGW VW is using IPSec offloading in addition. The following figure highlights the potential extensions to OPNFV interfaces that might be needed to enable hardware-independent data plane VNFs.

- What is in or out of scope
- Data plane acceleration use-cases other than packet-forwarding, encryption or transcoding are currently out of scope, which could be included in later phases.
- Management plane APIs are currently out of scope, for the sake of quick application, and could be included in later phases.
- The project can be extended in the following aspects in future
- To include more use-cases;
- To include management plane interfaces;
- To coordinate integrated testing and release testing results.
Dependencies:
- There is no similar proposal that is underway or being proposed in OPNFV or upstream project.
- Related upstream projects:
- ODP provides an SoC architecture for packet processing. ODP hides the differences between hardware implementation and provides unified APIs for some specific functions.
- DPDK is a similar project, which provides a set of libraries and drivers for faster packet processing on x86 architecture and has been ported to Open Power, ARM and even MIPS.
- OpenCL is a framework for writing programs that execute across heterogeneous platforms consisting of CPUs, GPUs, DSPs, FPGAs and other processors. OpenCL enabled a rich range of algorithms and programming patterns to be easily accelerated.
Committers and Contributors:
Names and affiliations of the committers:
- Lingli Deng (China Mobile, denglingli@chinamobile.com)
- Bob Monkman (ARM, Bob.Monkman@arm.com)
- Peter Willis (British Telecom, peter.j.willis@bt.com)
- Kin-Yip Liu (Cavium, Kin-Yip.Liu@caviumnetworks.com)
- Fahd Abidi (EZCHIP, fabidi@ezchip.com)
- Arashmid Akhavain (Huawei, arashmid.akhavain@huawei.com)
- Xinyu Hu (Huawei, huxinyu@huawei.com)
- Vincent Jardin (6WIND, vincent.jardin@6wind.com)
- François-Frédéric Ozog (6WIND, ff.ozog@6wind.com)
- Mike Young (myoung@wildernessvoice.com)
- Wenjing Chu (DELL, Wenjing_Chu@DELL.com)
- Saikrishna M Kotha (Xilinx, saikrishna.kotha@xilinx.com)
- Bin Hu (AT&T, bh526r@att.com)
- Parviz Yegani (Juniper, pyegani@juniper.net)
- Srini Addepalli (Freescale, saddepalli@freescale.com)
- Subhashini Venkataraman (Freescale, subhaav@freescale.com)
Planned deliverables
- Phase 1: (by 2015Q2) Use-cases, requirements and gap anlaysis
- Phase 2: (by 2015Q4) General framework specification, running code and testing report
Proposed Release Schedule:
- The first release is scheduled by 2015Q2 (tentatively).
- Not planned to be included in the first release of OPNFV.